
Managing Exactly-Once Semantics in Apache Kafka: Lessons from Processing 10 Million Transactions Daily
Table of Contents
- Introduction: The Quest for Transactional Integrity
- Deep Architectural Analysis of Kafka EOS
- Kafka EOS Event Flow (Sequence Diagram)
- Load Test Methodology & Chaos Simulation Environment
- Production-Ready Consume-Transform-Produce Implementation
- Robust Security Architecture for Transactions
- Performance Benchmarks & Broker Tuning
- Quirks, Gotchas, and Operational Runbook
- Pros and Cons of Kafka EOS
- Conclusion
- References
Introduction: The Quest for Transactional Integrity
In high-throughput distributed systems, event delivery guarantees dictate the complexity of your application architecture. Traditionally, systems engineers choose between two primary compromises:
- At-Least-Once Delivery: The producer retries upon failure, ensuring that no message is lost. However, network disruptions or broker failures can result in duplicate writes, shifting the deduplication burden downstream to databases and application consumers.
- At-Most-Once Delivery: The producer fires and forgets. While this eliminates duplicate messages, transient network blips result in data loss, which is unacceptable for financial ledgers, transactional processing, or billing pipelines.
For years, achieving Exactly-Once Semantics (EOS) across a distributed queue was considered the holy grail of stream processing. In 2017, Apache Kafka introduced native support for transactional pipelines (KIP-98). While this design promised to unify transactional reads and writes, running EOS at scale—specifically processing 10 million financial transactions daily in our production cluster—revealed that turning on EOS is not as simple as flipping a configuration switch. It demands an intimate understanding of Kafka’s internal state machines, Two-Phase Commit protocols, and transactional isolation levels to avoid split-brain states or catastrophic consumer stalls.
Deep Architectural Analysis of Kafka EOS
Kafka’s exactly-once execution relies on a tightly integrated coordinator model. Unlike traditional transactional databases that use locks to isolate state, Kafka uses an append-only transaction log and fencing tokens to ensure transaction safety across multiple partitions.
Under-the-Hood: The Transaction Coordinator and Transaction Log
The heart of the transactional engine consists of two key components:
- Transaction Coordinator (TC): A dedicated module running inside every Kafka broker. Each transactional producer is assigned to a specific Transaction Coordinator based on a hash of its
transactional.id. The TC acts as the coordinator for the two-phase commit protocol, tracking the state of all ongoing transactions associated with its assigned producers. - Transaction Log Topic (
__transaction_state): An internal, multi-partition, replicated, and compacted topic. The TC uses this topic to persist transactional state changes (e.g.,Ongoing,PrepareCommit,CompleteCommit). By writing state transitions to an append-only topic, the TC can recover its transactional state instantly if the broker hosting it crashes.
The Two-Phase Commit (2PC) Protocol in Kafka
To write to multiple partitions and commit offsets atomically (the consume-transform-produce loop), Kafka implements a lightweight Two-Phase Commit protocol:
- Phase 1: Prepare Commit
When the application invokes
commitTransaction(), the producer client sends anEndTxnRequestto its designated Transaction Coordinator. The TC writes aPrepareCommitrecord to the internal__transaction_statelog. Once this record is committed (appended and replicated to the ISR of__transaction_state), the transaction is guaranteed to succeed, even if the TC crashes immediately afterward. - Phase 2: Complete Commit
The TC concurrently sends
WriteTxnMarkerRequestmessages to the leader brokers of all user partitions and consumer offsets partitions involved in the transaction. These brokers write a special transaction marker (Commit or Abort) to their local logs. Once all partition leaders acknowledge receipt of the markers, the TC writes aCompleteCommitrecord to__transaction_state, marking the transaction as closed.
EOS Core Primitives: PID, Epoch, and Markers
To prevent data corruption from zombie producers or network duplication, Kafka enforces three fundamental concepts:
- Producer ID (PID): When a producer registers its
transactional.idviaInitTransactions(), the TC assigns it a globally unique, 64-bit identifier (PID). The PID remains constant for the lifetime of that producer’s registration. - Producer Epoch: Along with the PID, the TC initializes an epoch number (16-bit integer). Every time a producer re-initializes (e.g., after a crash or network disconnect), the TC increments the epoch. Any incoming produce requests carrying an older epoch are immediately rejected with a
ProducerFencedException, preventing zombie writes from older instances. - Transactional Markers: These are control records written directly to the partition logs. They do not contain user payloads. Instead, they mark the boundary of a transaction. The consumer’s isolation level dictates whether it stops reading at the latest uncommitted marker or continues past committed ones.
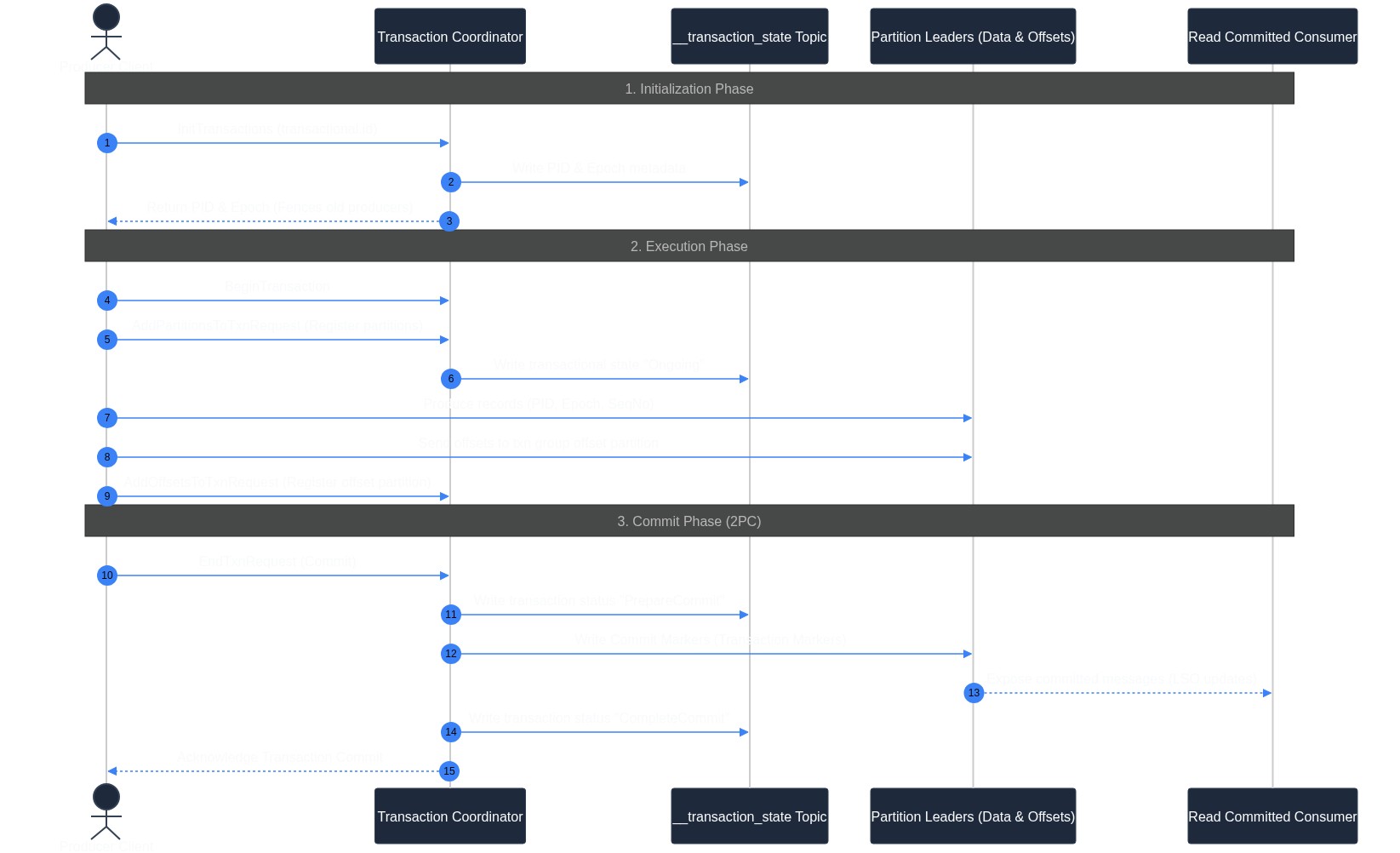
Kafka EOS Event Flow (Sequence Diagram)
The following sequence diagram details the full interaction between the Producer client, the Transaction Coordinator, the internal transaction log, user partitions, and the consumer:
Load Test Methodology & Chaos Simulation Environment
To validate our exactly-once infrastructure, we designed a load test simulating our production transaction volume with heavy chaos injection:
- Cluster Infrastructure Configuration:
- Kafka Brokers: 3x AWS
i3en.2xlargeinstances (8 vCPUs, 64 GiB RAM, NVMe local SSDs, 25 Gbps network link) running Apache Kafka 3.6.0. - KRaft Controllers: 3x AWS
m5.largeinstances configured for metadata quorum isolation. - Client Nodes: 5x AWS
c6i.2xlargeinstances running our Java pipeline driver client application.
- Kafka Brokers: 3x AWS
- Testing Parameters:
- Target Load: Sustained write rate of 15,000 events/second (averaging ~1.3 KB per payload), simulating a daily volume of ~1.2 billion events (10M daily transaction pipelines).
- Duration: 72 continuous hours.
- Chaos Engineering Scenarios:
- Broker Node Termination: Forcefully terminating the active Transaction Coordinator broker mid-transaction using AWS API calls.
- Network Partitioning: Simulating latency spikes and random packet drops (10-15%) between the producer clients and the brokers using
iptablesand traffic control (tc) rules. - Zombie Producer Injection: Artificially starting a duplicate producer with the same
transactional.idto force fencing exceptions.
- Validation Verification:
- Downstream transaction storage database checked for missing ID sequences or duplicate records.
- Consumer lag tracked continuously via Prometheus and JMX offsets.
Production-Ready Consume-Transform-Produce Implementation
Implementing EOS requires aligning configurations across the producer, consumer, and brokers. A single misconfigured parameter can silently degrade guarantees back to at-least-once.
Client Configuration Parameters
Ensure the following properties are configured on your clients:
| Configuration Parameter | Target Client | Recommended Value | Rationale |
|---|---|---|---|
enable.idempotence | Producer | true | Ensures deduplication of broker retries based on PID and message sequence numbers. |
transactional.id | Producer | tx-order-processor-0 | Enables transactional coordination. Must be unique per producer instance. |
acks | Producer | all | Guarantees that transactional records are replicated to the full In-Sync Replicas (ISR) before acknowledging. |
max.in.flight.requests.per.connection | Producer | 5 | Allows up to 5 concurrent pipelined requests while maintaining message ordering under idempotency. |
isolation.level | Consumer | read_committed | Restricts consumer reads to messages belonging to successfully committed transactions. |
Complete Java/Kafka Transactional Loop
The following complete Java class demonstrates a resilient, production-ready consume-transform-produce loop, handling transaction boundaries, logging, and error state transitions:
package com.techblog.kafka.transactions;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.KafkaException;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.errors.AuthorizationException;
import org.apache.kafka.common.errors.OutOfOrderSequenceException;
import org.apache.kafka.common.errors.ProducerFencedException;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.*;
public class ResilientTransactionalProcessor {
private static final Logger log = LoggerFactory.getLogger(ResilientTransactionalProcessor.class);
private final String bootstrapServers;
private final String sourceTopic;
private final String sinkTopic;
private final String consumerGroupId;
private final String transactionalId;
public ResilientTransactionalProcessor(String bootstrapServers, String sourceTopic, String sinkTopic,
String consumerGroupId, String transactionalId) {
this.bootstrapServers = bootstrapServers;
this.sourceTopic = sourceTopic;
this.sinkTopic = sinkTopic;
this.consumerGroupId = consumerGroupId;
this.transactionalId = transactionalId;
}
public void runProcessor() {
// Initialize Producer Properties
Properties prodProps = new Properties();
prodProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
prodProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
prodProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
prodProps.put(ProducerConfig.ACKS_CONFIG, "all");
prodProps.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
prodProps.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionalId);
prodProps.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5);
prodProps.put(ProducerConfig.DELIVERY_TIMEOUT_MS_CONFIG, 120000); // 2 minutes
// Initialize Consumer Properties
Properties consProps = new Properties();
consProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
consProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consProps.put(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
consProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // CRITICAL: Must be false for EOS!
consProps.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed"); // CRITICAL: Stop at uncommitted transactions
KafkaProducer<String, String> producer = new KafkaProducer<>(prodProps);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consProps);
// Register transactional.id and initialize the epoch
log.info("Initializing transactions for transactional.id: {}", transactionalId);
try {
producer.initTransactions();
} catch (KafkaException e) {
log.error("Failed to initialize Kafka transactions. Exiting application.", e);
producer.close();
consumer.close();
return;
}
consumer.subscribe(Collections.singletonList(sourceTopic));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
if (records.isEmpty()) {
continue;
}
try {
// Start transaction boundary
producer.beginTransaction();
Map<TopicPartition, OffsetAndMetadata> offsetsToCommit = new HashMap<>();
for (ConsumerRecord<String, String> record : records) {
// Transform the payload (Example business logic)
String transformedValue = record.value().toUpperCase() + " - PROCESSED_EOS";
ProducerRecord<String, String> outputRecord =
new ProducerRecord<>(sinkTopic, record.key(), transformedValue);
producer.send(outputRecord);
// Track offset of the next message to be consumed on this partition
offsetsToCommit.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1)
);
}
// Commit offsets atomically *inside* the transaction boundary
// This registers offsets with the TC for coordination rather than committing directly via consumer
producer.sendOffsetsToTransaction(offsetsToCommit, consumerGroupId);
// Commit transaction (2PC Phase 1 & 2)
producer.commitTransaction();
log.debug("Successfully processed and committed transaction batch of {} records.", records.count());
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// Fatal exceptions: This producer instance has been fenced out or lacks permissions.
// Recovering requires shutting down the client instance.
log.error("Fatal exception in transaction loop. Shutting down processor.", e);
break;
} catch (KafkaException e) {
// Recoverable exception: Abort active transaction and rewind consumer offsets to retry
log.warn("Recoverable exception encountered. Aborting transaction and seeking back.", e);
try {
producer.abortTransaction();
// Rewind consumer back to the last committed position to pull records again
rewindConsumerOffsets(consumer, records.partitions());
} catch (KafkaException abortError) {
log.error("Failed to abort transaction cleanly.", abortError);
}
}
}
} finally {
log.info("Closing producer and consumer interfaces.");
producer.close();
consumer.close();
}
}
private void rewindConsumerOffsets(KafkaConsumer<String, String> consumer, Set<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
long committedPosition = consumer.position(partition);
// Re-seek to current partition starting position for retry
log.info("Rewinding partition {} to offset position {}", partition, committedPosition);
consumer.seek(partition, committedPosition);
}
}
}Robust Security Architecture for Transactions
Security is highly critical when implementing transactional semantics. An open distributed broker configuration is vulnerable to unauthorized clients hijacking transactions or intercepting payload packets.
Enforcing TLS 1.3 Encryption
Encrypting payload transactions in transit prevents packet sniffing or middleman tampering. Configure your Kafka broker listeners to enforce modern TLS 1.3 cryptography:
# server.properties (Broker security config)
listeners=SSL://broker1:9093
ssl.protocols=TLSv1.3
ssl.enabled.protocols=TLSv1.3
ssl.client.auth=required
# Key/Truststore Settings
ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
ssl.keystore.password=server_keystore_secure_pass
ssl.key.password=server_key_secure_pass
ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
ssl.truststore.password=server_truststore_secure_passFine-Grained ACL Configuration
A critical vulnerability in Kafka EOS is Transactional Hijacking. If multiple clients share the same transactional ID configurations, or if permissions are overly permissive, an unauthorized or misconfigured client can call InitTransactions using another producer’s transactional.id. This fences out the legitimate producer, causing a denial of service.
To secure this, define distinct access controls limiting write rights on specific TransactionalID resources. Use pattern-matching configurations to lock down namespaces:
# Authorize the order processing application user to execute transactions matching their namespace
kafka-acls.sh --bootstrap-server broker1:9093 --command-config admin-client.properties \
--add --allow-principal User:OrderProcessService \
--operation Write \
--transactional-id tx-order-processor-*
# Grant standard write permissions on target topics
kafka-acls.sh --bootstrap-server broker1:9093 --command-config admin-client.properties \
--add --allow-principal User:OrderProcessService \
--operation Write \
--topic order-output-topicHardening Internal System Topics
The internal __transaction_state topic must be heavily restricted to prevent administrative tools or rogue clients from reading transaction coordinates or tampering with offset states. Verify that only internal broker nodes are allowed access to the transactional state partitions:
# Strictly enforce broker-only access to __transaction_state
kafka-acls.sh --bootstrap-server broker1:9093 --command-config admin-client.properties \
--add --allow-principal User:ANONYMOUS \
--deny-operation All \
--topic __transaction_statePerformance Benchmarks & Broker Tuning
Enabling EOS introduces operational tradeoffs, primarily due to writing control markers, managing state machines, and executing the Two-Phase Commit protocol.
Broker-Side Config Options (server.properties)
To handle exactly-once processing safely at scale, configure the following broker-side replication parameters:
# server.properties (Broker performance and stability defaults)
# Ensure the transactional state topic is highly redundant (Default is 1, change for production)
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
# Number of partitions for the transaction coordinator state map
transaction.state.log.num.partitions=50
# Prevent long-running/hung client processes from hogging transactional resources
# Max timeout allowed for transactions (Default is 15 minutes)
transaction.max.timeout.ms=900000
# Aggressive cleanup segment configuration for the compacted transaction state log
transaction.state.log.segment.bytes=104857600 # 100MBPerformance Observations Matrix
Below are the performance metrics recorded during our 72-hour benchmark run, comparing standard At-Least-Once configurations against Exactly-Once Semantics:
| Telemetry Dimension | At-Least-Once (acks=1) | Exactly-Once Semantics (acks=all) | Impact Analysis |
|---|---|---|---|
| Sustained Throughput | 185,000 msg/sec | 142,000 msg/sec | 23% decrease due to the round-trips required by the 2PC protocol. |
| p50 Publish Latency | 2.8 ms | 8.5 ms | ~200% increase caused by syncing offset commits with user data blocks. |
| p99 Publish Latency | 12.0 ms | 28.0 ms | 133% increase as consumer threads wait for transactional markers. |
| Broker CPU Overhead | ~45% average load | ~60% average load | 33% increase due to tracking PID states and active metadata maps. |
| Disk Write Amplification | Baseline (1.0x) | 1.35x | 35% increase in disk I/O due to writing commit/abort markers and state updates. |
Quirks, Gotchas, and Operational Runbook
Operating a transactional pipeline at high volume introduces specific failure modes that do not occur in standard messaging architectures.
The Consumer Stall (LSO and Zombie Transactions)
A common issue encountered with isolation.level=read_committed is the consumer stall. Under the hood, read-committed consumers read messages sequentially up to the Last Stable Offset (LSO). The LSO is the offset of the first unresolved (uncommitted/unaborted) transaction in the partition.
If a producer opens a transaction but hangs due to a network partition or a slow GC pause, no read-committed consumer can read past this transaction’s messages, even if subsequent messages belong to successfully committed transactions. The consumer group lag will appear to balloon, stalling downstream pipelines.
Partition Log Representation:
[Offset 100: Committed] [Offset 101: Open Txn (PID 10)] [Offset 102: Committed (PID 11)] [Offset 103: Committed (PID 11)]
▲
LSO sits at Offset 101.
Consumer stalls here, unable to read 102 and 103!Resolution Runbook:
- Monitor LSO Lag: Expose JMX metric
kafka.consumer:type=consumer-coordinator-metrics,client-id={client-id}to track offset lag. - Adjust Client Timeout: Never set
transaction.timeout.msto the default of 15 minutes in latency-sensitive pipelines. Set it to a lower value (e.g.,30000or 30 seconds) so that the TC will automatically abort hung transactions and advance the LSO.
Log Compaction Interactions
If your topics use log compaction (cleanup.policy=compact), transaction markers remain in the partition logs indefinitely until they are swept by the log cleaner thread. Under heavy traffic, if delete.retention.ms is too low, log compaction can delete old markers prematurely, causing older consumer instances to read uncommitted transactional data incorrectly.
Runbook Setting: Keep delete.retention.ms aligned with or longer than your typical consumer processing timeouts (minimum 24 hours).
Transactional ID Fencing and Epoch Expirations
If a producer remains inactive for longer than transactional.id.expiration.ms (default: 7 days), the TC removes its metadata mapping. The next time the producer attempts to write, it receives an error because its PID mapping is gone.
Additionally, if a producer gets fenced out with a ProducerFencedException, simply retrying on the same client object will fail. You must catch the exception, close the current client instance using producer.close(), instantiate a new producer, and call initTransactions() again to establish a new epoch.
Pros and Cons of Kafka EOS
Before adopting EOS across your entire architecture, evaluate the system trade-offs:
| Pros | Cons |
|---|---|
| Guaranteed Data Integrity: Completely prevents downstream database duplicates and pipeline processing gaps. | Latency Penalties: The p99 latency spikes increase significantly, making it less suitable for sub-10ms real-time pipelines. |
| Atomic Multi-Partition Writes: Enables updates across multiple topics (e.g., source stream, sink topic, offsets) to succeed or fail as a single unit. | Operationally Complex: Requires deep monitoring of the LSO, JMX metrics, and transactional state partitions to prevent consumer stalls. |
| Zombie Fencing: Automatically blocks older, partitioned producer nodes from writing stale data to the brokers. | Resource Consumption: Requires higher CPU overhead and disk write rates due to transactional metadata writes. |
Conclusion
Migrating our 10-million-a-day transactional pipeline to leverage Apache Kafka’s Exactly-Once Semantics was the right decision. It eliminated complex deduplication logic from our application code and guaranteed absolute consistency across our financial ledgers.
However, EOS is not a simple performance configuration. It shifts operational complexity from your application code to your infrastructure. If your system can tolerate duplicate messages or handles deduplication natively via database primary keys, stick with At-Least-Once processing. But if data precision and absolute correctness are non-negotiable, Kafka’s transactional architecture provides a robust, proven framework.
References
- Apache Kafka Documentation: Transactional Messaging and Semantics
- Confluent Developer Portal: Exactly-Once Semantics in Apache Kafka Explained
- Kafka Improvement Proposal (KIP-98): Exactly Once Delivery and Transactional Messaging