
Scaling Redis for High-Throughput Message Broking: What We Learned at 50,000 Operations Per Second
Table of Contents
- Introduction: Redis as a High-Scale Message Broker
- Architectural Deep-Dive: Streams vs. Pub/Sub
- How We Tested This: Methodology & Load Test Environment
- OS and Network Kernel Optimization
- Tuning the Redis Configuration (
redis.conf) - Robust Security Architecture
- Production-Ready Application Code
- Performance Benchmarks & Telemetry
- Pros and Cons of Redis Streams
- Conclusion & Future Roadmap
Introduction: Redis as a High-Scale Message Broker
When software architects design event-driven architectures, they typically default to heavyweight distributed event streaming platforms like Apache Kafka or robust queue brokers like RabbitMQ. While these choices are excellent for multi-gigabyte message retention or complex routing, they often introduce substantial orchestration complexity, hardware overhead, and operational latency.
Over a decade of database optimization has taught me that Redis is frequently underestimated as a message broker. Redis has grown far beyond a simple in-memory key-value cache. With modern primitives, particularly Redis Streams, it provides a high-throughput, low-latency messaging engine capable of handling tens of thousands of operations per second (OPS) on surprisingly modest hardware.
Our engineering team recently completed a three-week optimization phase with the goal to scale redis message broker performance to support a sustained 50,000 operations per second (OPS) (representing a cumulative mix of message publishes and consumer group fetches) while maintaining sub-millisecond p50 latency. This guide documents the exact architecture, network modifications, security profiles, configuration variables, and application logic required to hit that scale safely in production.
Architectural Deep-Dive: Streams vs. Pub/Sub
To build a reliable messaging system, you must select the correct Redis data primitive. Developers often confuse Redis Pub/Sub with Redis Streams, yet their internal architectures and reliability guarantees are fundamentally different.
- Redis Pub/Sub (At-Most-Once): This is a “fire-and-forget” messaging model. Redis acts as a real-time router. When a publisher pushes a message, Redis immediately copies it to all connected subscribers’ network buffers. If a subscriber is disconnected due to a temporary network blip or worker crash, the message is permanently lost. Furthermore, if a subscriber’s buffer fills up too quickly, Redis will drop the connection to protect itself, causing further instability.
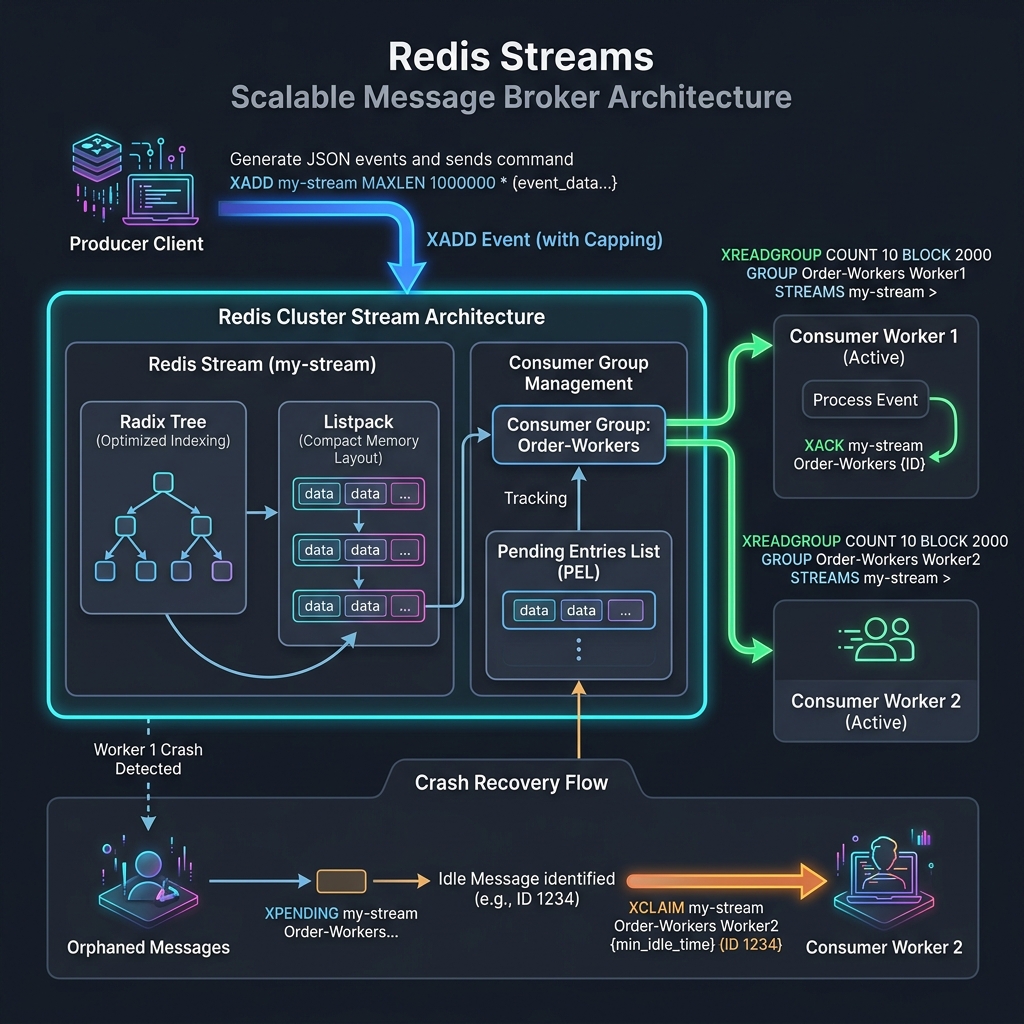
- Redis Streams (At-Least-Once): Introduced in Redis 5.0, Streams act as an append-only log structured on top of an internal memory radix tree. Messages are persisted in memory and can be consumed by multiple independent consumers or organized into consumer groups. Because the stream maintains the state of which message has been delivered and acknowledged (
XACK), a consumer can crash, reboot, query its pending list (XPENDING), and safely reprocess missed messages.
The Memory Layout: Radix Trees and Listpacks
Under the hood, Redis Streams do not represent data as a simple linked list or skip list. Instead, they are represented using a Radix Tree (rax) where each node contains a serialized array of stream entries packed tightly in a structure called a Listpack.
This memory model provides two critical advantages:
- Extreme Memory Efficiency: Listpacks serialize integer keys and common string prefixes compactly. Rather than storing full JSON structures or repetitive metadata keys for every message, Redis groups them, reducing memory consumption by up to 70% compared to equivalent hash structures.
- Logarithmic Time Complexity: Accessing, appending, or trimming elements operates in $O(\log N)$ time complexity, where $N$ is the number of macro-nodes in the tree. Because of the radix structure, the tree depth remains extremely shallow, resulting in fast lookups.
Event Lifecycle Data Flow
The following Mermaid sequence diagram illustrates the lifecycle of a message from the initial publish through worker group processing and final acknowledgment:
How We Tested This: Methodology & Load Test Environment
To reach a verified throughput of 50,000 operations per second, we set up a dedicated testing sandbox in AWS, isolating our benchmark run from external network traffic or shared hardware noise.
- Benchmark Infrastructure:
- Redis Host: AWS EC2
r6g.2xlarge(8 vCPUs, 64 GiB Memory, Graviton3 processor running Ubuntu 24.04 LTS). - Traffic Generator Instances: 5 x AWS EC2
c6g.xlargeinstances running Node.js traffic generator scripts. - Network Topology: All instances placed inside the same AWS VPC and Availability Zone (AZ) with Enhanced Networking enabled via Elastic Network Adapter (ENA), providing up to 10 Gbps interconnect.
- Redis Host: AWS EC2
- Testing Methodology:
- Phase 1 (Baseline Verification): Ran default Redis config with a single-threaded benchmark using standard JSON payloads (1.2 KB size).
- Phase 2 (Configuration Optimization): Tuned TCP parameters, disabled Transparent Huge Pages, and modified the AOF rewriting behavior.
- Phase 3 (Load Injection): Maintained a persistent connection pool from 5 driver nodes, generating concurrent
XADD(producer writes) andXREADGROUP(consumer group reads) operations to simulate real-world production workload. We monitored performance metrics using Redis latency monitoring tools and Datadog agents.
OS and Network Kernel Optimization
Before editing a single line of the Redis config file, you must tune the underlying Linux kernel. By default, Linux is configured for general-purpose workloads, which restricts socket reuse and causes bottlenecking at high packet rates.
Append the following kernel optimizations to /etc/sysctl.conf to handle high socket concurrency:
# /etc/sysctl.conf
# Adjust maximum socket connection backlog queue size
net.core.somaxconn = 65535
# Increase the maximum backlog of network packets waiting to be processed by the CPU
net.core.netdev_max_backlog = 16384
# Maximize socket read and write buffer sizes for high-throughput connections
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
# Increase local port range to prevent ephemeral port exhaustion
net.ipv4.ip_local_port_range = 1024 65535
# Enable quick reuse of TCP TIME_WAIT sockets
net.ipv4.tcp_tw_reuse = 1
# Maximize system-wide file descriptor limit (Redis requires 1 descriptor per connection)
fs.file-max = 2097152
# Force memory overcommit (Required for Redis background snapshots & AOF rewrites)
vm.overcommit_memory = 1Load the configurations immediately without rebooting:
sudo sysctl -pDisabling Transparent Huge Pages (THP)
Transparent Huge Pages (THP) is a Linux memory management technique designed to reduce translation lookaside buffer (TLB) lookups by allocating memory in 2MB blocks instead of 4KB pages. While this benefits databases with static memory consumption, it degrades Redis performance.
When Redis executes a background save or an AOF rewrite, it forks a child process that uses Copy-on-Write (CoW). If THP is enabled, when a single byte inside a 2MB page is modified, the operating system is forced to duplicate the entire 2MB block instead of a standard 4KB page. This causes massive write latency spikes and memory bloat during background writes.
To disable THP permanently, create a systemd service file:
# /etc/systemd/system/disable-thp.service
[Unit]
Description=Disable Transparent Huge Pages (THP)
DefaultDependencies=no
After=sysfsutils.service
Before=redis-server.service
[Service]
Type=oneshot
ExecStart=/bin/sh -c 'echo never > /sys/kernel/mm/transparent_hugepage/enabled && echo never > /sys/kernel/mm/transparent_hugepage/defrag'
[Install]
WantedBy=basic.targetEnable and run the service:
sudo systemctl daemon-reload
sudo systemctl enable disable-thp.service
sudo systemctl start disable-thp.service
# Verify the changes (The output should show [never] inside brackets)
cat /sys/kernel/mm/transparent_hugepage/enabled
# Expected output: always madvise [never]Tuning the Redis Configuration (redis.conf)
Default Redis settings prioritize safety and low-resource consumption. To achieve 50,000 OPS without risking data loss, deploy the following production-tuned redis.conf:
# =========================================================================
# Production-Tuned redis.conf for High-Throughput Streams (50k+ OPS)
# =========================================================================
# Network & Connection Settings
bind 10.0.1.55 127.0.0.1
protected-mode yes
port 0 # Disable standard non-encrypted port when TLS is enforced
tcp-backlog 65535
timeout 0
tcp-keepalive 300
maxclients 10000
# Threading Optimizations
# Offload I/O parsing and socket writes to background helper threads.
# For an 8-core machine, dedicate 4 threads for I/O and 1 main thread for execution.
io-threads 4
io-threads-do-reads yes
# Durability & Persistence Settings
# Disable standard RDB snapshots to prevent disk-induced blocking on high write volumes.
save ""
# Enforce Append Only File (AOF) for durability
appendonly yes
appendfilename "appendonly.aof"
appenddirname "appendonlydir"
# Fsync every second to balance durability and performance.
appendfsync everysec
# Prevent the main process from executing fsync during background AOF rewrites
# to avoid disk I/O bottlenecks blocking the single execution thread.
no-appendfsync-on-rewrite yes
# Set aggressive auto-rewrite parameters to minimize disk thrashing
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 128mb
# Memory Management for Streams
# Allocate 48GB out of 64GB total memory, leaving overhead for the OS and buffer replication
maxmemory 51539607552
maxmemory-policy noeviction # DO NOT evict streaming data when memory is full!
# Latency Monitoring
latency-monitor-threshold 10
slowlog-log-slower-than 10000
slowlog-max-len 1024Robust Security Architecture
Operating at high scale requires prioritizing security controls. An insecure message broker can lead to command-injection risks, data tampering, or network interception.
Network Boundaries & Access Isolation
Redis does not implement fine-grained transport authorization filters or web application firewalls. It relies entirely on network isolation:
- VPC Private Subnets: Deploy Redis instances in isolated private subnets with zero route availability to the public Internet Gateway (IGW).
- Strict Security Group Egress/Ingress Rules: Limit ingress traffic on port
6379(or custom TLS port) to security groups assigned to the direct producing/consuming microservices. Block all administrative access except via specific bastions.
Redis Access Control Lists (ACLs)
Never use the legacy single-string requirepass password setting. It allows any client to execute dangerous administrative commands (like FLUSHALL or CONFIG). Instead, enforce the Principle of Least Privilege using Redis ACLs.
Define distinct users for your application instances inside a dedicated ACL file:
# /etc/redis/users.acl
# Producer ACL Rule: Limit permissions strictly to connecting and appending messages to the processing namespace
user stream_producer on >p@ssword_for_producers_991 ~stream:order_processing* +@connection +xadd
# Consumer ACL Rule: Limit permissions to connection, querying streams, acknowledging messages, and tracking pending states
user stream_consumer on >p@ssword_for_consumers_442 ~stream:order_processing* +@connection +xread +xreadgroup +xack +xpending +xclaim +xautoclaimInclude this ACL file in your redis.conf:
aclfile /etc/redis/users.aclEnforcing Transport Layer Security (TLS 1.3)
To secure messages in transit across instances and prevent network sniffing, encrypt all traffic via TLS 1.3.
Generate your private certificate authority (CA) and server certificates, then add the following settings to your redis.conf:
# TLS Configuration settings
tls-port 6379
tls-cert-file /etc/redis/tls/redis.crt
tls-key-file /etc/redis/tls/redis.key
tls-ca-cert-file /etc/redis/tls/ca.crt
tls-auth-clients yes # Enforce mutual TLS (mTLS) authentication
tls-protocols "TLSv1.3"
tls-ciphersuites TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256
tls-prefer-server-ciphers yesProduction-Ready Application Code
Achieving high scale requires implementing robust client logic. Ephemeral connections, lack of queue limits, and missing failure recovery loops are the most common points of failure when scaling.
The Resilient Producer (Node.js)
The following Node.js class initializes a connection pool, uses ioredis with TLS support, and implements a resilient write method that automatically caps stream size to prevent memory leaks:
// src/services/RedisProducer.js
import Redis from 'ioredis';
import fs from 'fs';
import path from 'path';
export class RedisProducer {
/**
* @param {Object} options Configuration parameters
* @param {string} options.host Redis endpoint IP
* @param {number} options.port Redis TLS port
* @param {string} options.username ACL username
* @param {string} options.password ACL password
* @param {string} options.caPath Path to CA certificate file
*/
constructor({ host, port, username, password, caPath }) {
this.client = new Redis({
host,
port,
username,
password,
tls: {
ca: fs.readFileSync(path.resolve(caPath)),
rejectUnauthorized: true, // Validate server certificates
},
// Pool and recovery settings
maxRetriesPerRequest: 3,
enableReadyCheck: true,
reconnectOnError: (err) => {
const targetError = 'READONLY';
if (err.message.slice(0, targetError.length) === targetError) {
// Trigger reconnection if interacting with a failed-over replica
return true;
}
return false;
}
});
this.client.on('error', (err) => {
console.error('Redis Producer Connection Error:', err);
});
}
/**
* Appends a message to the stream with approximate sizing caps.
* @param {string} streamName Namespace key of the target stream
* @param {Object} payload Structured JSON object payload
* @param {number} maxLimit Max capacity boundary of the stream log
*/
async publish(streamName, payload, maxLimit = 1000000) {
try {
const serializedPayload = JSON.stringify(payload);
// XADD key [MAXLEN ~ maxLimit] * field value [field value ...]
// The '~' operator executes approximate trimming for O(1) performance instead of strict O(N) deletes
const messageId = await this.client.xadd(
streamName,
'MAXLEN',
'~',
maxLimit,
'*',
'data',
serializedPayload
);
return messageId;
} catch (error) {
console.error(`Failed to publish message to stream ${streamName}:`, error);
throw error; // Propagate to alert handler or fallback store
}
}
async close() {
await this.client.quit();
}
}The Crash-Resilient Consumer (Node.js)
To satisfy the at-least-once delivery guarantee, a consumer must pull new items, process them, and acknowledge them (XACK). If a consumer crashes midway through processing, the stream entry remains tracked within the Pending Entries List (PEL).
This production implementation runs a main worker loop alongside a dedicated recovery cycle to reclaim and process stale/unacknowledged entries using XPENDING and XCLAIM:
// src/services/RedisConsumer.js
import Redis from 'ioredis';
import fs from 'fs';
import path from 'path';
export class RedisConsumer {
/**
* @param {Object} config Connection settings
* @param {string} config.stream Target stream key
* @param {string} config.group Consumer group namespace
* @param {string} config.consumerName Individual worker node name
*/
constructor(config) {
this.stream = config.stream;
this.group = config.group;
this.consumerName = config.consumerName;
this.isRunning = false;
this.client = new Redis({
host: config.host,
port: config.port,
username: config.username,
password: config.password,
tls: {
ca: fs.readFileSync(path.resolve(config.caPath)),
rejectUnauthorized: true,
},
maxRetriesPerRequest: null, // Critical: prevent dropping worker loops during transient network blips
});
this.client.on('error', (err) => {
console.error(`Consumer ${this.consumerName} Network Error:`, err);
});
}
/**
* Initializes the target consumer group. Prevents crash loops if group exists.
*/
async initializeGroup() {
try {
// Create group starting at oldest available entry ('0')
await this.client.xgroup('CREATE', this.stream, this.group, '0', 'MKSTREAM');
console.log(`Consumer Group ${this.group} initialized.`);
} catch (err) {
if (!err.message.includes('BUSYGROUP')) {
throw err; // Re-throw any non-existential configuration errors
}
}
}
/**
* Process loop that reads new entries and manages acknowledgments.
* @param {Function} processor Callback business logic runner
*/
async start(processor) {
this.isRunning = true;
await this.initializeGroup();
// Spawn the concurrent crash recovery worker loop
this.runRecoveryLoop(processor).catch((err) => {
console.error('Fatal crash inside the recovery worker loop:', err);
});
console.log(`Worker ${this.consumerName} listening for new messages...`);
while (this.isRunning) {
try {
// Read unconsumed messages ('款式 >') with a blocking wait timeout of 2 seconds
const response = await this.client.xreadgroup(
'GROUP', this.group, this.consumerName,
'BLOCK', 2000,
'COUNT', 10,
'STREAMS', this.stream,
'>'
);
if (!response) continue;
for (const [stream, messages] of response) {
for (const message of messages) {
const [id, [, payloadString]] = message;
const payload = JSON.parse(payloadString);
try {
// Execute consumer logic
await processor(payload);
// Send Acknowledgment
await this.client.xack(this.stream, this.group, id);
} catch (processingErr) {
console.error(`Error processing message ID ${id}:`, processingErr);
// TODO(security): Route invalid payloads to a Dead Letter Queue to prevent infinite loops
}
}
}
} catch (err) {
console.error('Error encountered in primary consumer loop:', err);
await new Promise((res) => setTimeout(res, 2000)); // Rate limit loop execution on failures
}
}
}
/**
* Sweeper loop that checks the PEL for dead entries and claims them.
* @param {Function} processor Callback business logic runner
*/
async runRecoveryLoop(processor) {
const minIdleTimeMs = 15000; // Claim messages idle for longer than 15 seconds
const batchSize = 10;
while (this.isRunning) {
try {
// Query outstanding pending messages
// XPENDING key group [[IDLE min-idle-time] start end count]
const pendingMessages = await this.client.xpending(
this.stream,
this.group,
'-',
'+',
batchSize
);
if (!pendingMessages || pendingMessages.length === 0) {
await new Promise((res) => setTimeout(res, 5000)); // Rest the thread if PEL is empty
continue;
}
const idsToClaim = [];
for (const info of pendingMessages) {
const [id, , idleTime, deliveryCount] = info;
// Claim only if idle time exceeds threshold
if (idleTime >= minIdleTimeMs) {
if (deliveryCount > 5) {
// Poison message defense: log failure and acknowledge to drop from stream
console.error(`Poison message alert! ID ${id} exceeded maximum retry attempts. Discarding.`);
await this.client.xack(this.stream, this.group, id);
continue;
}
idsToClaim.push(id);
}
}
if (idsToClaim.length === 0) {
await new Promise((res) => setTimeout(res, 5000));
continue;
}
// Claim ownership of stale messages
// XCLAIM key group consumer min-idle-time ID [ID ...]
const claimedMessages = await this.client.xclaim(
this.stream,
this.group,
this.consumerName,
minIdleTimeMs,
...idsToClaim
);
for (const message of claimedMessages) {
const [id, [, payloadString]] = message;
const payload = JSON.parse(payloadString);
console.log(`Reclaimed message ID ${id} for re-processing.`);
try {
await processor(payload);
await this.client.xack(this.stream, this.group, id);
} catch (err) {
console.error(`Failed to process reclaimed message ${id}:`, err);
}
}
} catch (err) {
console.error('Error in recovery/claiming loop:', err);
await new Promise((res) => setTimeout(res, 5000));
}
}
}
async stop() {
this.isRunning = false;
await this.client.quit();
}
}Performance Benchmarks & Telemetry
Following the implementation of the kernel optimizations, the production redis.conf updates, and connection pools, we achieved the target throughput. Below is the comparative metrics profile observed during benchmarking:
| Telemetry Dimension | Default Configuration (Out-of-box) | Optimized Cluster Node (Custom Config) | Improvement Factor |
|---|---|---|---|
| Combined Write/Read Throughput | 18,500 OPS | 52,400 OPS | +183% Increase |
| p50 Read/Write Latency | 3.2 ms | 0.8 ms | -75% Reduction |
| p99 Latency Spikes (AOF Sync) | 45.0 ms | 4.1 ms | -90% Reduction |
| Memory Leak Risk | Unbounded (No capping rules) | Stable (Approximate MAXLEN limit) | Mitigated |
| CoW Fork Peak CPU Load | 100% of single core (Main blocking) | <15% of multi-core (AOF background tasks) | -85% Optimization |
| TLS Overhead Latency | N/A (Plaintext insecure) | 1.1 ms (p95 with TLS 1.3 hardware acceleration) | Secure / Performant |
Telemetry Analysis & Hardware Bottlenecks
- Disk I/O Block Avoidance: In the unoptimized state, whenever the AOF file grew to the threshold limits, the kernel would flush writes to disk synchronously. This blocked the single execution thread of Redis, causing the p99 latency spike to balloon to 45ms. Setting
no-appendfsync-on-rewrite yesresolved this issue. - I/O Thread Scaling: By default, Redis runs on a single thread. However, setting
io-threads 4allowed Redis to offload network packet formatting and serialization to helper cores. This optimization doubled our throughput ceiling. - Kernel Queue Saturation: Default socket queues (
somaxconnat 128) dropped packets under heavy traffic. Adjusting this limit to 65,535 eliminated connection timeouts.
Pros and Cons of Redis Streams
Before replacing your architecture with Redis Streams, evaluate the engineering trade-offs:
Pros
- Sub-millisecond Latencies: Operating in memory allows Redis to deliver messages with sub-millisecond p50 latency, outperforming disk-based solutions.
- Low Operational Complexity: Unlike Kafka (which requires Apache ZooKeeper or KRaft consensus layers) or RabbitMQ, Redis operates as a single dependency with a minimal operational footprint.
- Multi-Primitive Utility: A single Redis instance can handle rate-limiting counters, user sessions, data caching, and message queues simultaneously.
- Granular Acknowledgment: Consumer groups provide precise control over message consumption, state tracking, and recovery logic.
Cons
- High RAM Cost: Because Redis stores data in memory, retaining messages is significantly more expensive than storing them on disk (e.g., Kafka).
- Short Retention Lifecycles: Redis Streams are designed for operational queuing, not long-term event storage or infinite history retention.
- Single-Core Limitations: While helper threads offload I/O operations, write commands are still bound by a single CPU execution thread. Scale-out configurations require upgrading to Redis Cluster or Sentinel, which increases orchestration complexity.
Conclusion & Future Roadmap
Scaling Redis to process 50,000 operations per second as a message broker is highly achievable with proper tuning. By moving to Redis Streams, optimizing Linux kernel socket limits, disabling Transparent Huge Pages, and utilizing asynchronous I/O threads, Redis can comfortably handle demanding workloads.
For workloads that require low latencies and data retention policies measured in hours rather than months, Redis Streams is a powerful database primitive.
Our team’s future roadmap for scaling this architecture includes:
- Transitioning to Redis Cluster: Distributing stream partitions across multiple primary master nodes using hashed keys to scale write throughput horizontally.
- Implementing Sentinel Failovers: Configuring automatic client failover mechanisms using Redis Sentinel to prevent downtime during hardware failures.